

Outsourcing Sub-Grid Cloud Physics to Neural Networks
Diagram of a two-layer feedforward neural network.
Deep Neural Networks: Powerful machine learning emulators of high-dimensional nonlinear functions disrupting industry and climate modeling
Modern machine learning (ML) methods are proving to have interesting breakthrough potential for how sub-grid processes can be represented in next-generation global climate simulations.
Background
The details of air turbulence matter deeply to the planetary climate and the regional water cycle. For instance, it remains uncertain how shallow clouds, stemming from turbulent air motion near the Earth’s surface, will respond to future warming. Changes in these clouds could brighten the planet thereby helping to stabilize the warming, or dim it, which would amplify the warming. The fate of the Amazon’s regional hydroclimate is equally unclear. How rainfall patterns will change as surface vapor fluxes decrease and heat fluxes increase, which can happen over tropical rainforests as plants adapt physiologically to elevated CO2, is equally uncertain. The Amazon’s rainfall patterns also depend on what the turbulent eddies will do in response to changing surface fluxes, which modify regional water vapor transport (Langenbrunner et al., 2019).
Unsatisfying approximations of boundary layer turbulence in global climate models seem inescapable for the foreseeable future. Although E3SM is developing a global storm-resolving model that can explicitly represent processes at a 1 to 4 km horizontal scale, the most important cloud-forming boundary layer turbulence processes occur at scales of less than 100 meters horizontally. Computationally, this is extraordinarily expensive to simulate explicitly (Schneider et al., 2017). Having more strategies available to the modern climate modeler to confront these seemingly “unparameterizable scales”, preferably via information gained by explicitly resolving them, is an advantage.
This is why it is so exciting to explore modern ML methods as a means of emulating – potentially at vastly reduced expense – such climate-critical processes. To date the job of a global atmospheric modeler has been difficult – simulating the whole atmosphere for decades. In this case realistic, fine-resolution 3D turbulence calculations are too much even for the formidable supercomputers available within E3SM. But if the job changes to making just short simulations for training machine learning emulators – fast statistical models which closely approximate the more comprehensive and expensive simulations – scientists can do better justice to turbulence physics with existing resources.
This is not a new idea; using ML to emulate sub-grid physics dates back to Chevalier (Chevallier et al., 1998) who proved the concept for radiative transfer two decades ago, as well as pioneering work by Krasnopolsky who explored its potential to accelerate weather and climate predictions (Krasnopolsky et al., 2006, Krasnopolsky et al., 2013). However, it is not until the past three years that new ML optimization algorithms have led to captivating proofs-of-concept beginning to succeed in viable research simulations.
Current Advances
A growing group of Earth system and computer scientists at the University of California, Irvine (UCI) are using ML methods to emulate sub-grid convection using training data from “multi-scale”, or “superparameterized” (SP) atmospheric simulations, such as can be generated from the E3SM’s Exascale Computing Project (Hannah et al., 2020). (Superparameterization involves putting many Cloud Resolving Models (CRMs) within each grid cell of a Global Climate Model (GCM). For more information see Walter Hannah’s description of superparameterization.)
Some might question the usefulness of taking data from such models for training emulators, due to the imperfections of SP. Indeed, superparameterized models produce at best only idealized information about turbulent phenomena because the convection in their thousands of embedded Cloud Resolving Models (CRMs) is artificially assumed to be locally periodic and two-dimensional (Grabowski 2001, Randall 2003, Khairoutdinov et al., 2005). Today, certainly for deep convection, the advent of uniformly-resolved storm-resolving models provides a better training data source for such scales (Satoh et al., 2019). But to be explicit about fine-resolution boundary layer turbulence, which requires orders of magnitude more computational intensity per unit area than storm-resolving physics, the strategic idealizations of SP are one of the only ways to imagine sidestepping assumption-prone parameterizations (Parishani et al., 2017, 2018).
For the purpose of testing the limits of ML emulators, training data from superparameterized models also provides a helpful advantage of a clear predictor-corrector relationship. There is a well-defined “large-scale” with causatively unambiguous links to a “sub-grid-scale” (an embedded CRM) nested within it. This sidesteps many technical issues that can complicate the use of ML on more sophisticated training data such as coarse-grained uniformly-resolved simulations (Brenowitz et al., 2019).
All this makes it relatively easy to explore the basic question of the “parameterizability” of explicitly resolved deep convection using ML methods, towards their eventual use in richer settings. As a first step, the UCI team, together with collaborators from Columbia University, recently asked whether “deep learning” is viable for emulating classical global superparameterization of 1 kilometer-scale convective physics (Gentine et al., 2018). Deep learning can be thought of as a high-dimensional, non-linear, multi-variate regression, which happens to be achieved via neural networks (NNs) with more than a few layers. It has become a popular ML architecture in computer science thanks to training optimization algorithms tailored to GPU-based hardware developments that have made these methods remarkably accessible for software engineers and graduate students. Deep NNs (DNNs) have proved exceptionally skillful and scalable for tasks like image recognition (Chollet 2017).
Approach
To address the convection emulation question the UCI team first ran a superparameterized aquaplanet out for a few years. (An aquaplanet is an idealized configuration of a global atmospheric model in which the planetary surface is completely covered with water.) From the superparameterized aquaplanet’s high-frequency output researchers created a training library containing all of the salient driving information (i.e. large-scale temperature and vapor profiles, incoming sunlight and surface fluxes) from the exterior resolved scale as well as all the resulting convective responses (i.e. local heating and moistening profiles) from each of the 8,192 embedded CRMs.
The UCI and Columbia scientists then asked whether the actual CRM responses to large scale forcing – despite being the average of stochastic predictions obtained from integrating nonhydrostatic fluid dynamics interacting with parameterized microphysics – could nonetheless be “fit” by a crude, deterministic neural-network.
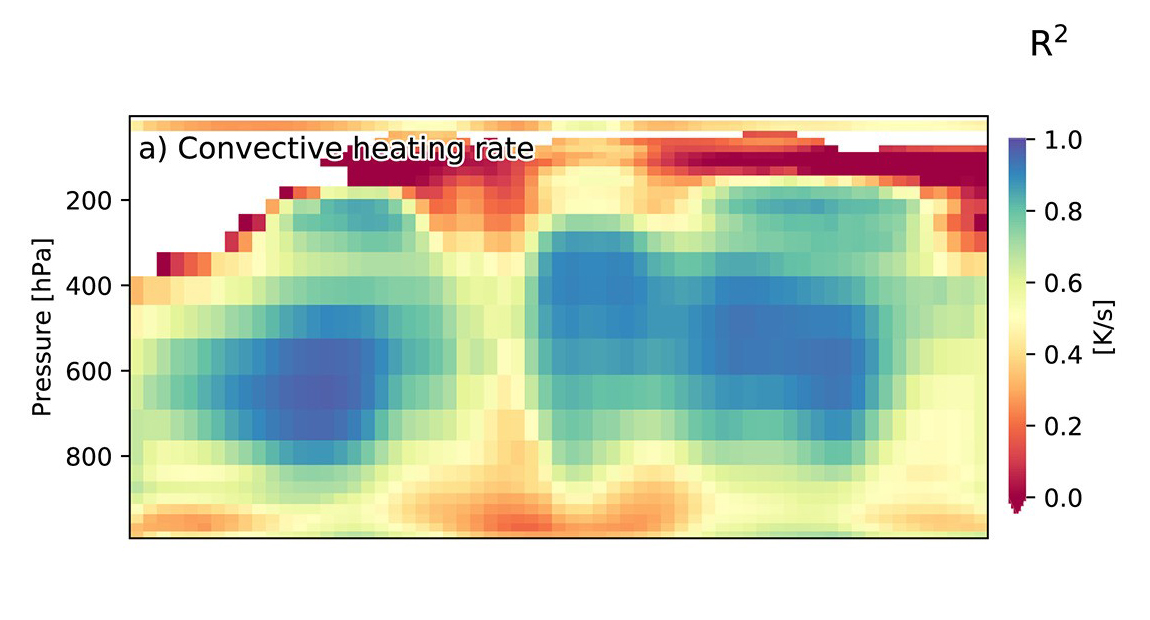
Figure 1. “Offline” skill, i.e. holdout validation data error, for the first aquaplanet DNN emulator trained on superparameterization, showing competitive skill (R^2 > 70%) in important mid-tropospheric regions; reproduced from Gentine et al. (2018).
The answer turned out to be “surprisingly, yes!” As shown in Figure 1, a DNN can be coaxed through its architecture and training environment, given millions of samples, to fit over seventy percent of the variance of the actual convective heating, measured at the 30-minute sampling scale. Importantly, this skill occurs within strategic mid-tropospheric regions where convective heating couples to planetary dynamics such as over the Intertropical Convergence Zone (ITCZ) and extratropical storm tracks. These results come from testing the DNN, once trained, against a hold-out validation dataset that was excluded from the training exercise, i.e. a separate year of aquaplanet simulation in this case.
A more important test is to actually try free-running global climate simulations that use these pre-trained DNN emulators instead of SP calculations to handle sub-grid convective physics. In at least one successful instance, a talented PhD student found a remarkable prognostic result during a research visit to UCI: Rasp et al. (2018) managed to coax a DNN architecture that, despite its imperfections, and even when used in free-running multi-year predictions, reproduced virtually the same mean climate as benchmark results (Fig. 2).
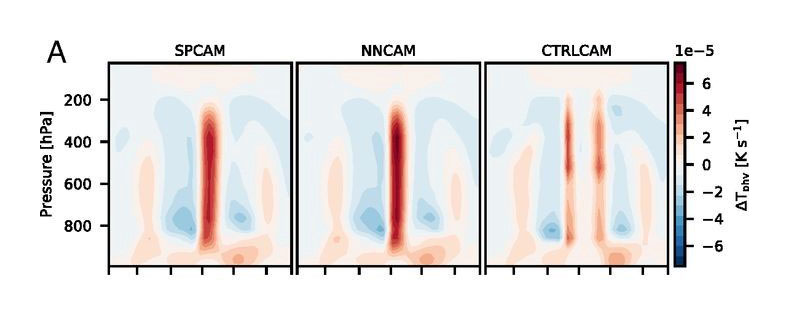
Figure 2. “Online” skill as evidenced in the good match between (left) Zonal mean diabatic heating rate from actual superparameterized physics in benchmark aquaplanet simulations compared against (center) free-running, multi-year simulations in which the SP is replaced with a neural network, and (right) simulations in which the SP is replaced with a standard empirical model for convection. Reproduced from Rasp et al. (2018).
More strikingly, the simulations also produced the same equatorial wave spectrum as free-running superparameterized calculations (Fig. 3), at an order of magnitude less computational expense! This included hallmark effects of classical superparameterization, such as a robust Madden-Julian Oscillation and moist atmospheric Kelvin Waves that travel at appropriate speeds. Such prognostic tests are now proof that DNNs can successfully emulate the desired physics of explicit deep convection, even across its diverse geographic regimes, to the degree needed to produce accurate multiyear predictions.
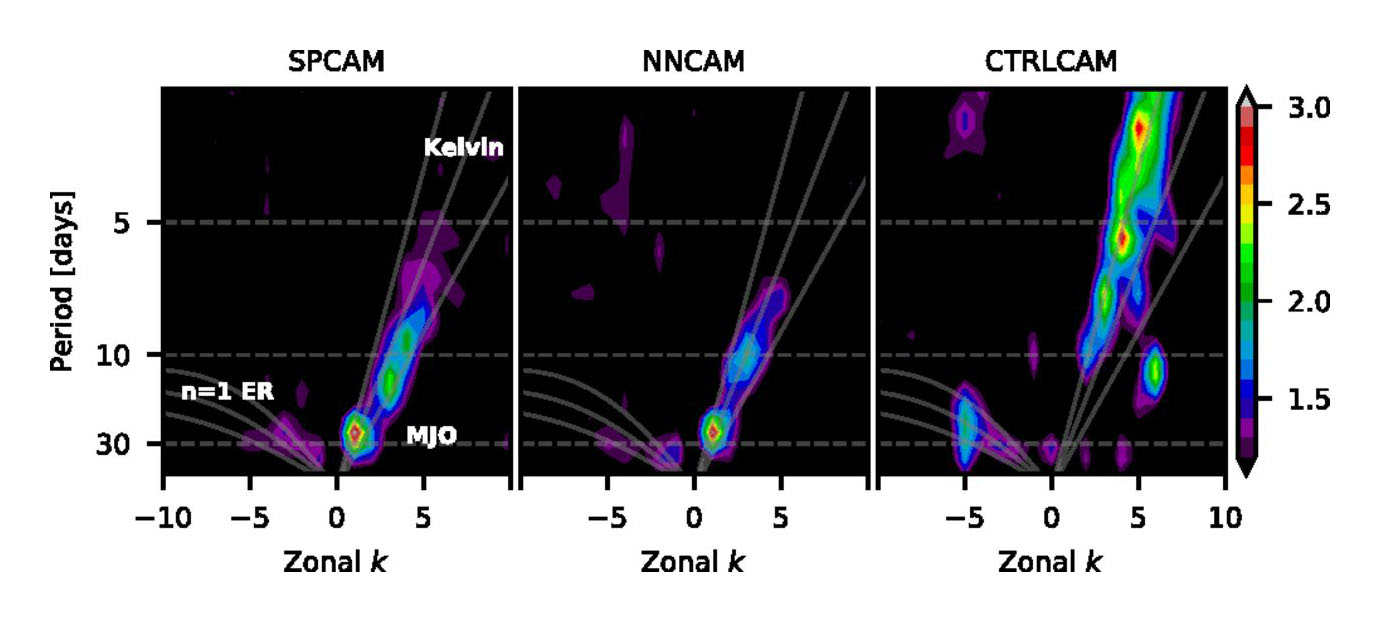
Figure 3. As in Figure 2, but for the equatorial wave spectrum showing a comparable Madden-Julian Oscillation and moist Kelvin Wave dispersion relationship in SPCAM (left) and NNCAM (center), while the Madden-Julian Oscillation is absent when a standard empirical model for convection is used (right).
But there are important issues yet to address if ML-based parameterizations are to ever become an operational reality within projects like E3SM.
For example, conserving energy is mission-critical. Data-driven methods, unlike the data they’re trained on, do not know to obey conservation laws. Leaks of column enthalpy in the Rasp et al. (2018) emulator frequently exceeded 50 W/m2. This is obviously unacceptable for operational climate prediction. The problem is less severe for random forest-based ML methods (RF), which can also produce remarkable prognostic aquaplanet results even from more challenging training data (Yuval and O’Gorman 2020) and which obey linear constraints by definition. But RFs have their own limitations in scaling to extremely large data volumes making DNNs of continued interest for the future. For DNNs, Beucler et al. (2020) have demonstrated a promising solution: with some strategic intervention within the actual neural network architecture it is possible to enforce conservation of mass, enthalpy, and water to within machine precision. Empirical results so far suggest that training skill is otherwise not impacted. Thus, achieving conservation properties appears at this stage to be a solvable problem, even for DNNs, and including nonlinear constraints if needed. But it has yet to be tested in ultimate prognostic tests.
Unsolved Problems
For now, the biggest unsolved problem is learning how to reliably achieve prognostic success that is reproducible and robust. Today it is still the case that most prototype ML emulators, once coupled to a prognostic host model, lead to crashes (Brenowitz et al., 2020). This is entangled with a bit of a reproducibility crisis. In the UCI team’s most recent work to reproduce the skillful prognostic tests of Rasp et al. (2018), even after just minor enhancements of the CRM training data, success has proved frustratingly difficult (Brenowitz et al., 2020).
The roots of this issue may turn out to be in the gory technical details, which can be more easily fixed or manipulated, than some high-level, overarching problem that is harder to solve. More testing is needed to know. One problem is the generally empirical nature of ML research and the nontrivial time it takes an individual to tinker with NN training settings to find good fits. Another is the practical difficulty of testing prototype emulators, which are usually trained in a modern Python environment, as online kernels in Fortran-based climate codes. Since this has typically required human intervention, there has not been much biodiversity in the spectrum of ML emulators that have actually been tried online. For an empirical art, there are remarkably few data points!
Thankfully, both problems are benefitting from new semi-automated software packages. Formal hyperparameter tuning packages are key to solving these problems since, given enough GPUs, they can quickly allow hundreds of candidate neural network architectures to be surveyed at scale using random or hierarchical searches. As an example, the Earth system scientists in the UCI team have been collaborating with computer science colleagues on campus, who are opening their eyes to the power of an elegant automated python package called “Sherpa” (Hertel et al., 2020). It has proved useful in multiple physical science and biological research disciplines. Meanwhile Ott et al. (2020) have just unveiled a new software library called the “Fortran-Keras Bridge” that dovetails with Sherpa by taking the pain out of translating large ensembles of candidate DNN models for testing in Fortran-based climate models, to reveal their coupled trade-offs at scale. This is just now putting a dent in the “reproducibility crisis” (Fig. 4) and allowing the provocative results of Rasp et al. (2018) to be reproduced in richer aquaplanet settings, thanks to testing a diverse sample of candidate NNs. There is much still to learn about what it takes to actually train performant emulators of convection at scale as the community embraces wider use of such tools.
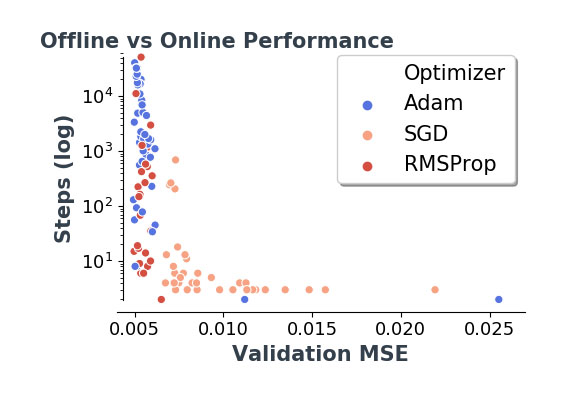
Figure 4. [Reproduced from Ott et al., 2020] Proof-of-concept results from a formal hyperparameter search (via Sherpa software made in the Computer Science department at UCI) that identified DNN emulators of sub-grid climate model physics, using 25-epoch training trials applied to ~ 40M samples of training data from a coarse aquaplanet simulation. Offline validation error (x-axis) for each of ~100 candidate DNN architectures discovered via the Sherpa tuning algorithm is shown on the x-axis and compared to a measure of “online” error (y-axis) as measured in timesteps until model failure when the DNNs are coupled via the new “Fortran-Keras Bridge (FKB)” library to a host Global Climate Model (GCM). Blue dots at top left indicate successful results that resolved a stubborn instability in this context. Adam, SGD and RMSProp are different optimizers that train neural networks to solve problems via gradient descent.
For now, what makes this type of ML research so exciting is that, as a community, we are likely only on the verge of discovering what the actual potential of ML emulation may be for sidestepping conventional parameterization. Time will tell whether the new workflow above can succeed in the richer limits of real-geography or turbulence-permitting training data that would be of most scientific interest. Meanwhile one thing seems clear – with these additional degrees of freedom will come increasing demands for GPU resources to train ever larger ensembles of candidate NNs with increased representational space. Thanks to DOE’s investment in leadership GPU computing facilities, the E3SM Project appears especially well-positioned to push this frontier. Among other activities emerging, the UCI team is delighted to be working with a growing team of scientists across multiple national laboratories who share enthusiasm about probing the potential of ML for this application. Exploratory collaborations between UCI and the Enabling Aerosol-cloud interactions at GLobal convection-permitting scalES (EAGLES) and Exascale Computing Project (ECP) teams are ongoing.
Funding
- DOE SciDac and Early Career Programs (DE‐SC0012152 and DE‐SC0012548)
- DOE Exascale Computing Project (17-SC-20-SC)
- NSF (AGS‐1734164, OAC-1835863)
- Extreme Science and Engineering Discovery Environment supported by NSF grant number ACI-1548562 (charge numbers TG-ATM190002 and TG-ATM170029)
Contacts
- Mike Pritchard and Tom Beucler, University of California, Irvine
Additional Collaborators
- Pierre Gentine, Columbia University
- Stephan Rasp, Technical University of Munich
- Griffin Mooers, University of California, Irvine
- Chris Bretherton and Noah Brenowitz , Vulcan, Inc and University of Washington
- Pierre Baldi and Jordan Ott and Galen Yacalis, University of California, Irvine
- Paul O’Gorman and Yani Yuval, Massachusetts Institute of Technology