

New Argonne Workflow Control System for CMIP Data Generation
A new, streamlined workflow for generating Coupled Model Intercomparison Project Phase 6 (CMIP6) datasets from native E3SM simulation output has been established at Argonne National Laboratory.
Background
E3SM simulation teams routinely produce vast amounts of native raw output data which is archived uniformly at the National Energy Research Scientific Computing Center (NERSC) on their High Performance Storage System (HPSS). To facilitate intercomparison between E3SM data and other CMIP models archived on Earth System Grid Federation (ESGF), this native data must be converted into CMIP6-compliant datasets before publishing to ESGF. (This involves far more than mere formatting; time-series must be produced for many new CMIP6 variables defined in terms of formulas over native model-output variables.) Previously, all simulation archives were transferred en masse to local storage for processing, resulting in significant data duplication. Until recently, this workflow operated at Lawrence Livermore National Laboratory (LLNL), where substantial local disk resources enabled all simulation archives to be held and processed in-house. The retirement of these disk resources created the need to move the workflow, and Argonne—being close to the site of data publication—was the natural choice for this transition.
What’s new
Given an arbitrary list of CMIP6 dataset_ids, indicating datasets to be produced, the new workflow incrementally and conditionally retrieves only the native data necessary to produce the indicated datasets, retrieving archives from NERSC only as needed and minimizing data transfers, archive extractions, and local storage requirements. Automated checks ensure that transfers are not initiated if there is insufficient disk space, and both extracted data and archives are deleted when no longer needed. No longer relying on a workflow that assumed all simulation archives would be held locally, this refactored process better aligns with operational checkpoints. This approach replaces a previous, cumbersome system of manual activities, supporting an uninterrupted flow of continuous processing.
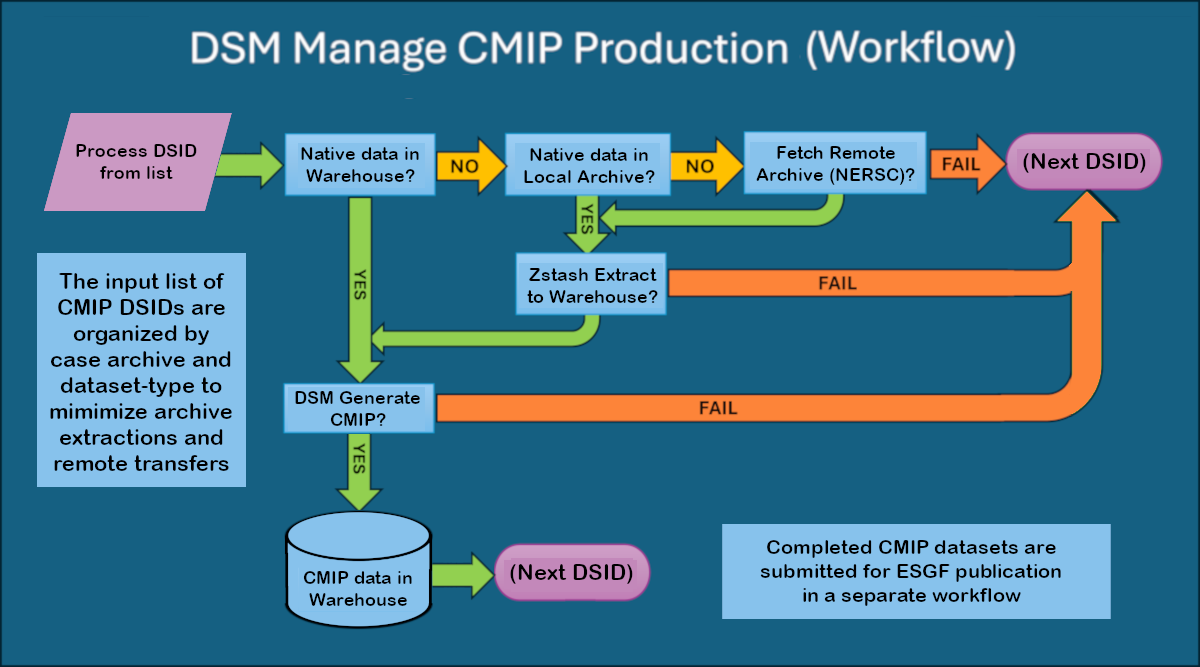
Figure 1. The Data State Machine (DSM) workflow at Argonne to manage CMIP production.
When a list of desired CMIP6 datasets is provided, the workflow (Fig. 1) checks for the required native data in the local Argonne “warehouse.” If the data is present, CMIP6 generation can proceed. If not, the system automatically determines whether to extract previously fetched data from the local archive or to fetch the required archives from NERSC using zstash+Globus. Once processed, the CMIP6 datasets are stored locally for subsequent publication to ESGF, with the workflow ensuring data integrity and efficient resource use throughout the process.
Additionally, the core CMIP6 generation process (the “DSM Generate CMIP” step in Fig. 1, distinct from the overarching workflow managing archives and native datasets) has been completely revised to create and execute fully-configured variable-specific scripts that apply conditional regridding and then submission of e3sm_to_cmip jobs to slurm/srun parallel processing. This revamped processing dispenses with the previous collection of Common Workflow Language (CWL) scripts that had been employed previously, and are now deprecated.